始めて技術同人誌を執筆しました
技術同人誌を執筆しました
先日の冬コミ(C97)にて、人生で初めて技術同人誌というものを書いて頒布しました。 https://webcatalog-free.circle.ms/Circle/14808053
頒布した本は 『新しい挑戦をしたい時に見る本 Vol.2』 といい、BOOTHで基本無料でお求めいただけます。 booth.pm
基本無料というのは以下のような理念で頒布しているからです。
『新しい挑戦をしたいときに見る本』シリーズとは、まんてらスタジオに集まっているクリエイター達が、好き勝手に自分の書きたい物を提示して、好き勝手に技術書を書き、それを我々で一つの本にして出版しているプロジェクトの事です。 このプロジェクトの最大の特徴として、挑戦本は無料で頒布しております。この本を本当に求めている人からはお金を頂かずに、このプロジェクトを応援したい人から支援を頂いて活動をしております。
本誌は@mannteraさん主催のまんてらスタジオに集まった計10人のエンジニア/デザイナーによる合同誌の第2弾です。 私はChapter10の「対話型日記BOT開発を通じて学ぶ自然言語処理入門」を担当しました。
【#C97 冬コミ情報】
— まんてら@VTuber再準備中 (@manntera) December 29, 2019
『新しい挑戦をしたいときに見る本』の紹介!
Web系企業プログラマ@Sashimimochi343 さんの、
対話型日記BOT開発を通じて学ぶ自然言語処理入門
を紹介します!#挑戦本#まんてらスタジオ#DeepLearning #自然言語処理#コミケ97 #C97お品書き #コミックマーケット97 pic.twitter.com/FCsILqgn6i
経緯
最近は、コミケに加えて技術書展の盛り上がりにより良質な技術同人誌がとても増えてきています。 私も何度か一般参加で会場に足を運びましたが、出版社発行の書籍として世に出回っていないTipsやネット上に散らばっている知見を体系的に学べるので毎回楽しみにしています。 単純に共通の趣味を持った人たちが集まって話しているという雰囲気を味わうだけでもよい刺激がもらえます。 こういった光景を見ているうちに、自分も一筆認めてみたいという衝動に駆られました。 そんな折、まんてらスタジオさんのほうからお声掛けをいただきこの度、参加することにしました。
本誌(自分の担当章)の概要
対話形式で日記が書けるボット開発を通じて自然言語処理の基礎とちょっとしたその応用について書いています。
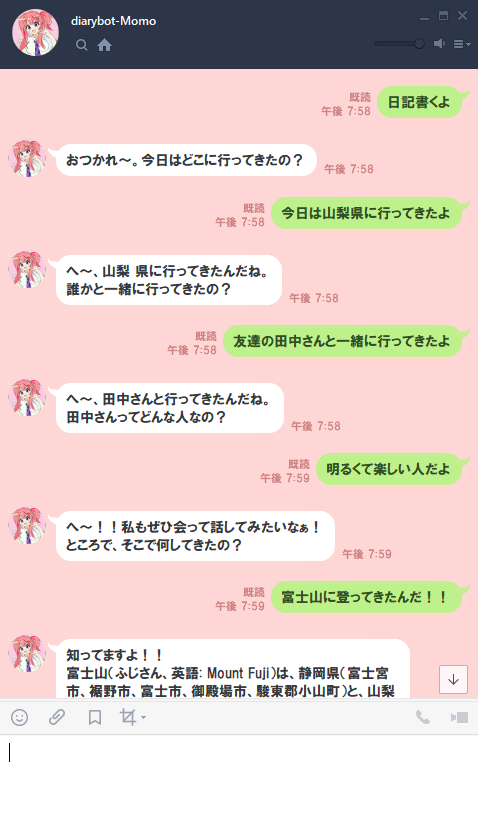
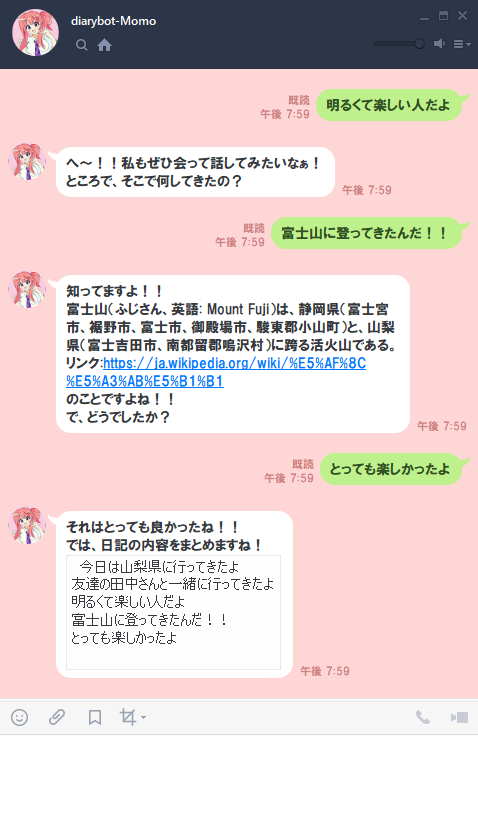
本誌のタイトル通り、読者の方に本誌の内容をキッカケに新しい挑戦をしてもらえるように導入から丁寧に解説しました。
私自身、自然言語処理を学び始めて1年弱の初心者ではありますが、そんな人でも1年あればこれくらいならできるんだと感じていただき、これから始めようか迷っている人が後押しができればという思いで執筆しました。
せっかく書くなら単なるやってみたで終わらせたくなかったので、理論と実装の両面から個人的な勘所をたくさん詰め込みました。 その結果、全体の約1/3のページを占める大作になってしまいました。

また、本誌の中で紹介しているデモボットも公開しています。 github.com
もし、少しでも興味を持っていただけたなら、ぜひお手に取っていただけると幸いです、 その際は、感想をお聞かせいただけると大変喜びます。 それでは、また。
2019年個人的注目アドベントカレンダー(随時更新)
企業系
- Retty
- 富士通 今年もDeepLearing100選あるのかな?
- はてな
- Yahoo Japan
開発・研究系
- Discord 最近趣味の開発テーマの主軸なので ←12/24分に参加いたしました
- NLP
- NLP2 こちらも最近の個人開発のもうひとつの軸 公開1日でほぼほぼ埋まるほど人気のテーマ!?
- Deep Learning論文紹介 Advent Calendar 2019
- 今年読んだ一番好きな論文2019
Herokuでpython+mecab+ffmpegを使う
はじめに
最近、ちまちまとdiscord上で動くchatbotを作っているのですが、やっぱり公開サーバーで動かさないと日常的に使えないのでHerokuにデプロイすることにしました。 ただ、無料枠のHerokuで動かそうとするといろいろと解決しないといけない課題が多くてひたすら逃げていたのですが、ようやく重い腰を上げてデプロイしたので、手順をメモがてら残してみたいと思います。
必要な要件
を使っているのでこれらが動かせる環境が必要。
Herokuでpython+mecabの環境づくりは下記の記事を参考にしました。 herokuでpython+django+scikit-learn+mecab(1) ffmpegの環境づくりはこちらを参考にしました。 DiscordBotでyoutubeの音声をボイスチャットに流す
いざ、構築
condaとherokuの複数のビルドパックを使うのでheroku-buildpack-multiでアプリを作成する必要があります。気になるのはこのリポジトリがメンテナンスを終了していることでしょうか。
This buildpack is no longer actively maintained. The associated functionality exists natively on the Heroku platform. Please refer to https://devcenter.heroku.com/articles/buildpacks and https://devcenter.heroku.com/articles/using-multiple-buildpacks-for-an-app for documentation.
まず、ローカルでリポジトリを作ります。
$ git init $ heroku create --buildpack https://github.com/heroku/heroku-buildpack-multi
使用するビルドパックは以下の通りです。
https://github.com/Sashimimochi/conda-buildpack.git https://github.com/sunny4381/heroku-buildpack-linuxbrew.git https://github.com/jonathanong/heroku-buildpack-ffmpeg-latest.git https://github.com/Crazycatz00/heroku-buildpack-libopus.git
scikit-learnなどのCコンパイラを必要とするライブラリも使いたいのでcondaのビルドパックがいるのですが、pythonのバージョンを固定したいので以下のリポジトリをforkして自前で用意することにしました。
https://elements.heroku.com/buildpacks/teamupstart/conda-buildpack
minicondaのバージョン一覧はこちらから見れます。
https://repo.continuum.io/miniconda/
ちなみに、ものによっては、以下のような最近のpipでは廃止されたオプションが付いていてビルドエラーを起こすので注意。
pip install -r requirements.txt --exists-action=w --allow-all-external | indent
- https://github.com/heroku-python/conda-buildpack/issues/36
- https://stackoverflow.com/questions/57546079/no-such-option-allow-all-external-when-deploying-a-django-app-to-heroku-wit
上記の.buildpacksでheroku-buildpack-linuxbrewを入れたのでbrewが使えるようになっています。brewで入れたいパッケージを.cellarで指定します。
mecab mecab-ipadic open-jtalk
condaおよびpipでインストールするライブラリはconda-requirements.txtやrequirements.txtに書いておきます。
Herokuにmecab-pythonをインストールしようとすると案の定、エラーが出ました。 herokuでpython+django+scikit-learn+mecab(1)では手動でインストールしていましたが、今回は、python3系を使うわけですし、mecab-python3ならはいったので、代わりにこちらを入れます。 Heroku mecabインストール時にエラー
あとはパスを指定してデプロイします。
$ heroku config:add LD_LIBRARY_PATH=/app/.linuxbrew/lib $ heroku config:set MECAB_PATH=/app/.linuxbrew/lib/libmecab.so $ git add . $ git commit -m 'initial' $ git push heroku master
滞りなく、一連のデプロイが進んで無事うまくいったように思えたのですが、最後のメッセージであえなく撃沈。
-----> Compressing... ! Compiled slug size: 3009.8M is too large (max is 500M). ! See: http://devcenter.heroku.com/articles/slug-size ! Push failed
https://devcenter.heroku.com/articles/slug-compiler#slug-size 上記のメッセージにもある通り、Herokuの無料枠のストレージサイズが500MBなのでデプロイ時にこの範囲内に収める必要があります。
容量を食っているのが、機械学習モデルだったので、Herokuでこれを動かすにはモデルのサイズを圧縮しておく必要がありました。 中でも一番のファイルサイズが大きいのがWord2Vecだったので、こちらのライブラリを使ってモデルサイズを圧縮しました。 50,000語程度にまで絞れば約60MBまで圧縮できます。 https://github.com/yagays/minify_w2v 重要語は以下から選択しました。 日本語を読むための語彙データベース Ver. 1.1 その他にもcacheを削除するなどいろいろ工夫の余地はありそうです。
これでリポジトリの容量をかなり圧縮できました。
大量のライブラリを使ってしまったせいで、これでもデプロイ時にpip installまでしてしまうと上限の500MBを超えてしまったので、起動時にpip installが走るようにしておきました。
bot: bash run.sh
pip install -r requirements.txt python app.py
以上で、なんとか無事に動きました。
トラブルシューティング
Herokuリポジトリにログイン
Herokuにログインしてマニュアル操作するときは以下のようにすればログインしてbashコマンドが使えます。
heroku run bash
ログの確認
デプロイ後にアプリケーションのログが見たければ以下のコマンドで確認できます。
$ heroku logs
やっぱりはてなブログを自分のホームページに埋め込みたい
※2021/1/18に複数のサイトからRSSを取得したい場合のやり方を末尾に追記しました。
経緯
長年お世話になっていたYQLが残念ながら2019年1月に無期限のサービス停止を発表されました。Yahooさん、今までありがとうございました。
On Jan. 3, 2019, YQL service at https://t.co/g4W9RhdMLk will be retired. YQL based services that use https://t.co/g4W9RhdMLk, including users of https://t.co/5IkUaEykdl, will no longer operate. Yahoo Weather API users see the tweet below for info about continuing your service.
— Y! Developer Network (@ydn) 2018年12月31日
したがって、再び新しい方法を考える必要が出てきました。
私情ではありますが、最近ようやくReactを勉強し始めましたので、今回はReactを使ったRSSフィードの取得・表示方法を考えてみました。
着手当初はどうしようと戦々恐々だったのですが、比較的簡単に行けそうだったのでご紹介してみます。
やり方さえ分かれば、30分もかからずにできてしまうと思います。(私は調べる過程を含めると半日くらいかかりました。)
※Reactのチュートリアルすらまともに理解しているか怪しい初心者がトライ&エラーで考えた方法なので、ベテランの方からすれば滅茶苦茶な実装になっているかもしれません。ご容赦ください。
とりあえずRSS情報を取得して表示する
何はともあれ、まずは完成形をお見せします。無事、ブログのタイトルとリンクを取得して飛べるようになりました。
見てくれ部分は私のUIセンスの問題なので、これなんかよりいくらでも格好よくできると思うので、ぜひ各々アレンジしてみてください。
(というか、格好いいデザインができたら教えてください)

環境は
$ create-react-app -V 2.1.1
を使っています。
で、肝心の実装ですが、あれこれ調べてみたところ、手っ取り早く実現できそうなものにRSSParserというライブラリがありました。
ということで今回は、このRSSParserを使います。
www.npmjs.com
ライブラリのインストールは
npm i rss-parser
とかで出来ます。
ひとまず、RSS情報を取ってきてコンソールに表示させてみます。
取り急ぎ動作確認したいならcreate-react-appでプロジェクト?を作ってApp.jsに書き込めば動作確認は出来ます。
import React from 'react'; //中略 const RssParser = require('rss-parser'); //importではなくrequireで呼びます const url = 'http://t-n-clark.hatenadiary.jp/feed' const rssParser = new RssParser(); rssParser.parseURL(url) .then((feed) => { console.log(feed); }); .catch((error) => { console.error('Get Failed', error); }); class App extends Component { render(props) { const classes = this.props.classes; //...後略
Chromeのデベロッパーツールで確認すると、ちゃんとコンソールに取得したRSS情報が出ています。
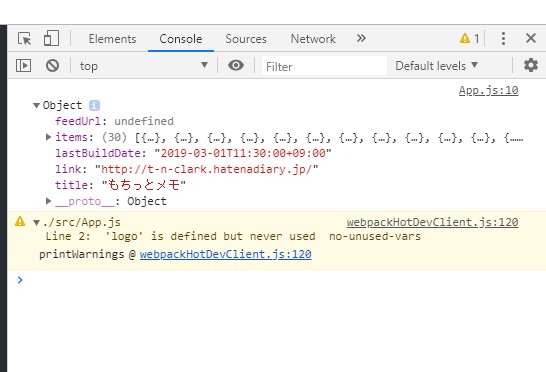
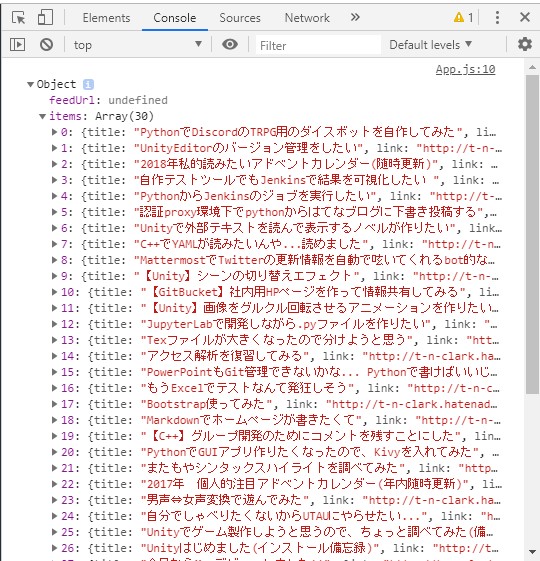
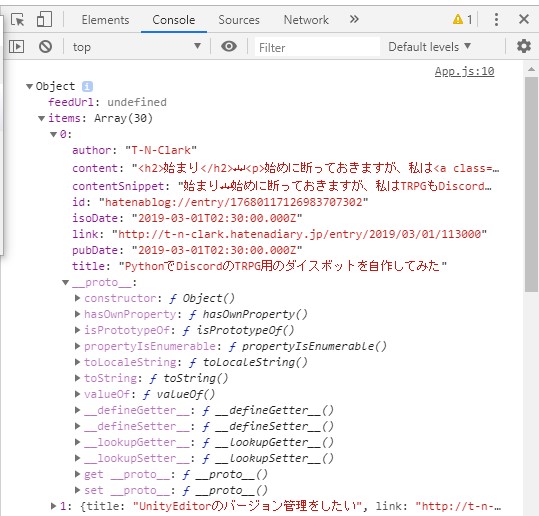
ざっと見たところ、記事のタイトルとかの情報はこのitemsに入っているみたいです。
各ブログのトップURL/rss
もしくは
各ブログのトップ/feed
で取得出来ます。
例えば、このブログのRSSは
https://t-n-clark.hatenadiary.jp/feed
で取れます。
※HTTPでも取れそうな気がするのですが、HTTPだとスマホではちゃんと取れなかった表示されなかったので、HTTPSをおすすめします。
(端末ではなく、ブラウザの問題かもしれませんが... これが関係するのでしょうか?)
bookmark.hatenastaff.com
Qiitaであれば、
https://qiita.com/アカウント名/feed.atom
で取得出来ます。
例えば、こんな感じ
https://qiita.com/Sashimimochi/feed.atom
ただ、HTTPSの場合はクロスドメイン制約があるので、URLの前にCORS(cross-origin resource sharing)PROXYをつけてあげる必要があります。
上記のRSSParserのページを読んだところ、こんな感じで行けそうです。
const CORS_PROXY = "https://cors-anywhere.herokuapp.com/" //はてなブログならこっち const url = CORS_PROXY + 'https://t-n-clark.hatenadiary.jp/feed' //Qiitaならこっち const url = CORS_PROXY + 'https://qiita.com/Sashimimochi/feed.atom'
あとは取得した情報をstateに格納してJSX内で呼び出してみます。 先ほどデバッグ用に出していたConsoleへの出力はもういらないので消しても大丈夫です。
import React from 'react'; import { Component } from 'react'; import PropTypes from 'prop-types'; import './App.css'; /*RSSParserのインスタンス生成*/ const RssParser = require('rss-parser'); const url = "http://t-n-clark.hatenadiary.jp/feed" const rssParser = new RssParser(); class App extends Component { /*コンストラクターの定義*/ constructor(props) { super(props); this.state = { contents: [], }; this.componentDidMount = this.componentDidMount.bind(this) } /*stateにrssParserの結果をバインド*/ componentDidMount() { rssParser.parseURL(url) .then((feed) => { const data = feed.items; console.log(data); this.setState({ contents: [...data] }); }) .catch((error) => { console.error('Get Failed', error); }) } render(props) { const classes = this.props.classes; /*表示するコンテンツの形に合わせてstateの中身を書きだす(mapで拡張forループみたいに使う)*/ const contents = this.state.contents.map(content => { return <div> {content.title} /*{content.pubDate} 公開日(Qiitaなら{content.published})*/ /*{content.link} ページリンク*/ </div> }); return ( <div className="App"> <header className="App-header"> {contents} /*ここに出力*/ </header> </div> ); } } App.propTypes = { classes: PropTypes.object.isRequired, }; export default App;
これで無事RSS情報を取得して表示できるようになりました。

あとは、これを自分なりに装飾していくことになります。
見てくれを整える
参考になるかはわかりませんが、冒頭にあった私なりの装飾を紹介してみます。 主にMaterial-Ul(のCard)とreact-moment(※momentではありません)を使っています。 material-ui.com www.npmjs.com
×こっちではありません。 www.npmjs.com
それぞれ
# Material-UI (@4.0.1) $ npm install @materail-ui/core # react-moment (@0.9.2) $ npm i react-moment
でインストールできます。 まずは、ほぼほぼMaterial-Ulの公式ドキュメントにあるCardのサンプルに先程のRSSデータを流し込みます。
import React from 'react'; import { Component } from 'react'; import PropTypes from 'prop-types'; import Card from '@material-ui/core/Card'; import Button from '@material-ui/core/Button'; import Avatar from '@material-ui/core/Avatar'; import red from '@material-ui/core/colors/red'; import { withStyles } from '@material-ui/core/styles'; import Grid from '@material-ui/core/Grid'; import './App.css'; import { CardHeader, CardContent } from '@material-ui/core'; const RssParser = require('rss-parser'); const url = "http://t-n-clark.hatenadiary.jp/feed" const rssParser = new RssParser(); const styles = theme => ({ blog: { margin: 20, padding: 20, marginTop: 10, }, blogcontent: { overflowY: 'scroll', height: '200px', }, avatar: { backgroundColor: red[500], }, }); class App extends Component { constructor(props) { super(props); this.state = { contents: [], }; this.componentDidMount = this.componentDidMount.bind(this) } componentDidMount() { rssParser.parseURL(url) .then((feed) => { const data = feed.items; console.log(data); this.setState({ contents: [...data] }); }) .catch((error) => { console.error('Get Failed', error); }) } render(props) { const classes = this.props.classes; const contents = this.state.contents.map(content => { return <Card> <CardHeader avatar={<Avatar arial-label="Blog" className={classes.avatar}>も</Avatar>} subheader={content.pubDate} title={content.title} /> <CardContent key={content.id}> <Button size="small" color="primary" href={content.link}>Read More</Button> </CardContent> </Card> }); return ( <div className="App"> <header className="App-header"> <Grid container> <Grid item xs={12} sm={7}> <div className={classes.blog}> <h3>はてなブログ更新情報</h3> <div className={classes.blogcontent}>{contents}</div> </div> </Grid> </Grid> </header> </div> ); } } App.propTypes = { classes: PropTypes.object.isRequired, }; export default withStyles(styles)(App);
今回はタイトル(title)と日付(pubDate)とリンク(link)のみを使っていますが、
スペースとの相談次第では、サマリー(contentSnippet)とか入れてもいいかもしれません。
(RSSParserってサムネイル画像も取れているのでしょうか?もし取れているならサムネイル画像を使うのもありだと思います。)
はてブのfeed側の仕様なのか、RSSParser側の仕様なのか確かめてませんが、デフォルトだと最新30件?分のRSS情報が取れているみたいです。
なので、それをそのまま表示すると中々悲惨なことになります。
Material-UIにもbootstrapのようなグリッドシステム的なものがありますので、Gridで幅調整をすることが出来ます。
Gridを使えば多少のレスポンシブデザインに対応出来ます。
あとはoverflowY: 'scroll'で表示枠のサイズを指定したりしてみました。


これで個人的には、おおよその見た目は及第点くらいにはなったのですが、時刻表示が世界標準のままで見にくいです。
そこで、react-momentというライブラリを使ってこれを整形します。
RSSParserで取ってきた日付をフォーマットを指定してMomentタグで挟んであげればいいみたいです。
例えば、YYYY/MM/DDにしたければ、
import Moment from 'react-moment' <Moment format="YYYY/MM/DD">{content.pubDate}</Moment>
とやれば、
# 変換前 2019-03-01T02:30:00.000Z # 変換後 2019/03/01
に出来ました。

他にもいろいろあるみたいなので、公式のサンプルを参考にお好みのフォーマットにしてみてください。
ちなみにですが、Twitterの埋め込みなら、専用のライブラリ(私はreact-twitter-widgetsを使っています)を使えばもっとお手軽にできてしまいます。 www.npmjs.com

あとがき
以上で、React限定&初心者によるメチャメチャ実装ではありますが、ひとまず再びブログの更新情報を埋め込めるようになりました。
この方法はあと何年使えるんだろう…?
先日、Googleから発表されたiframeに代わるPortalsタグを使えば、現在稼働中のクラシカルなページでもSPA並みにサクサク遷移できるようになるみたいです。
まあ、まだearly stageみたいなので私は試していませんが…
docs.google.com
blog.uskay.io
私事ですが、今回RSSフィードの実現方法を変える必要があったので、この機にいっそのことホームページの方も一新しようかなと思っています。
今見返すと一昔前のような見た目ですし。無事、一新したら紹介するかもしれません。
暫定版→http://clarkphys.html.xdomain.jp/index.htmlclarkphys.html.xdomain.jp
それではまた。
2021/1/18追記
効率が良いかは自信がありませんが、複数のサイトからRSS情報を取得する場合は以下のようにurlとcomponentDidMount()を書き換えればできます。
ポイントは次の2つです。
setStateで情報を更新するときに、既存のstateと新規取得情報を結合しておく- サイト内では順番通りになっているが結合したときに日付がバラバラなので、sortしておく
const RssParser = require('rss-parser'); const CORS_PROXY = "https://cors-anywhere.herokuapp.com/" // 取得したいURLをListで定義しておく const urls = [ CORS_PROXY + 'https://t-n-clark.hatenadiary.jp/feed', CORS_PROXY + 'https://qiita.com/Sashimimochi/feed.atom' ] const rssParser = new RssParser(); class Profile extends Component { constructor(props) { super(props); this.state = { contents: [], }; this.componentDidMount = this.componentDidMount.bind(this) } componentDidMount() { urls.map((url) => { rssParser.parseURL(url) .then((feed) => { // 新たに取得したfeedを取り出す const data = feed.items; // 既存のstateを取り出しておく var feeds = this.state.contents // 既存のstateに新規で取得したfeedを1つずつ追加する data.map((d) => { feeds.push(d) }) // 日付でsortする feeds.sort(function (a, b) { if (a.pubDate < b.pubDate) { return 1; } if (a.pubDate > b.pubDate) { return -1; } return 0 }); // stateをupdateする this.setState({ contents: feeds }); }) .catch((error) => { console.error('Get Failed', error); }) }) }
次回
PythonでDiscordのTRPG用のダイスボットを自作してみた
始まり
始めに断っておきますが、私はTRPGもDiscordもにわか勢です。
最近、身内でTRPG(主にCoC)をぼちぼちやるのですが、毎回ダイス振って判定するのってメンドくさいよねって話になりました。 セッション環境はdiscordを使い始めたので、discord上で動くbotにしようということになりました。正直なところ、既に先人のお方が作られた素晴らしいものがあるので「discord-bcdicebot使えばよいのでは?」というのが賢い選択だと思います。 ですが、ポンコツの私には使い方がわからなかったので、勉強も兼ねて友人に手伝ってもらいながら作ってみました。
Python + Googleスプレッドシート (+ Heroku)で実現しています。 ソースコード全体はGitHubに晒しておきます。
PythonからGoogleスプレッドシートにアクセスする
ダイスを振るだけなら不要なのですが、技能の成否判定も自動でしたいのでキャラクターシートをGoogleスプレッドシートに作って判定することにしました。 Googleスプレッドシートの操作方法はこちらを参考にしました。
こちらを参考にOAuth用のクライアントIDを作成してjsonファイルをダウンロードするところまで進めます。 セキュリティを度外視するならGoogle Apps ScriptでHTTPリクエストを受け付けるという方法もあるかとは思います。
スプレッドシートの仕様は適当でこんな感じです。
| 技能 | 合計値 | 純減 | 初期値 | 職業P | 興味P |
|---|---|---|---|---|---|
| HP | 9 | 0 | 9 | 0 | 0 |
| MP | 7 | 0 | 7 | 0 | 0 |
| SAN | 60 | 0 | 60 | 0 | 0 |
| db | 1d4 | 0 | 1d4 | 0 | 0 |
| こぶし | 50 | 0 | 50 | 0 | 0 |
| 図書館 | 50 | 0 | 25 | 25 | 0 |
初期値の決め方は下記を参照しました。
この中で使うのは技能と合計値のカラムです。これを以下のような感じでpythonから取得します。
def get_gs(): scopes = ['https://www.googleapis.com/auth/spreadsheets'] json_file = './hoge.json'#OAuth用クライアントIDの作成でダウンロードしたjsonファイル credentials = ServiceAccountCredentials.from_json_keyfile_name(json_file, scopes=scopes) http_auth = credentials.authorize(Http()) # スプレッドシート用クライアントの準備 doc_id = 'doc_id'#これはスプレッドシートのURLのうちhttps://docs.google.com/spreadsheets/d/以下の部分です gs = gspread.authorize(credentials) gfile = gs.open_by_key(doc_id) #読み書きするgoogle spreadsheet return gfile
ユーザーごとにでシートを切り替えられるようにします。シート名はなんでも良いのですが、私はdiscordから自動でシートを切り替えられるようにdiscordのIDをシート名にしています。
def get_charactor(sheet_name): gfile = get_gs() worksheet = gfile.worksheet(sheet_name) charactor = {} #技能名カラム cell_keys = worksheet.col_values(1) #合計値カラム cell_values = worksheet.col_values(2) for k,v in zip(cell_keys, cell_values): charactor[k] = v return charactor
ここまででスプレッドシートの設定は終了です。
Discord側のBOTを作る
次にDiscordの設定をしていきます。
Bot作成
DiscordのBOTの作り方はこちらを参考にさせていただきました
- DiscordでBOT作成メモ w/ discord.py
- PythonでDiscord botを作る 【discord.py解説】
- DiscordのBotをPythonで作ってみた
- Pythonで実用Discord bot(discord.py解説)
メッセージを取る
discordのメッセージ欄に特定の入力があったらダイスを振るようにします。入力形式は以下の仕様にします。ダイスを振るトリガーはdiceにします。
dice 1d100 技能名
これで受け取ってメッセージを返す待機botの処理を実装します。
client = discord.Client() client_id = conf['client_id'] @client.event async def on_ready(): print('Logged in') print('-----') @client.event async def on_message(message): # 開始ワード if message.content.startswith('dice'): # 送り主がBotではないか if client.user != message.author: info = parse('dice {}d{} {}', message.content) if info: if info[1].isdecimal() and info[0].isdecimal(): dice_num = int(info[0]) dice_size = int(info[1]) key = info[2] # メッセージを書きます m = message.author.name + ' ' if key == '一時的狂気': m = temp_madness() elif key == '不定の狂気': m = ind_madness() elif key == 'dice': m = simple_dice(dice_size, dice_num) else: chara = get_charactor(str(message.author)) msg, result = judge(chara, key, dice_size, dice_num) m += msg if result: d = damage(chara, key) else: d = None if d is not None: m += '\nダメージ: ' + str(np.sum(d)) + ' = ' + str(d) # メッセージが送られてきたチャンネルへメッセージを送ります await client.send_message(message.channel, m) client.run(client_id)
ダイス
ダイス振る部分を実装します。単純に入力したダイスを振るものと成否判定をするものの2種類用意します。
まず、1〜dice_sizeまでの一様整数乱数を1つ生成します。
def dice(dice_size): num = np.random.randint(1, int(dice_size)) return num
単純にダイスを振る場合は次のようにしています。上記のダイスをdice_num回分振ります。2d6なら1d6のダイスを2回振っています。あとでメッセージ表示の際に個別のダイス結果も見たいのでダイス結果はnumpy.arrayにしています。合計値はnp.sumで計算します。msgはdiscordに返すメッセージです。
def simple_dice(dice_size, dice_num): dice_val = np.array([], dtype=np.int64) for i in range(dice_num): dice_val = np.append(dice_val, dice(dice_size)) msg = 'dice: ' + str(np.sum(dice_val)) + ' = ' + str(dice_val) return msg
discord上ではこんな感じになります。

成否判定をするときもsimple_diceをベースに実装します。
成否判定
スプレッドシートから引っ張ってきた情報を参照して成否判定をさせます。 取得したスプレッドシートの情報は辞書型にして持たせておきます。
charactor = {
'HP': 9,
'MP': 7,
'SAN': 60,
'こぶし': 50,
'図書館': 50
}
と言っても、インスタンス生成とかしているわけではないので、判定のたびにスプレッドシートからデータを参照しているので、たぶん非効率的です。
処理の流れは
- 入力メッセージからダイスのサイズと数を取得する
- ダイスを振ってダイス値を取得する
- 技能値をダイス値を比較する
といった感じです。ちなみに卓ルールで5以下でクリティカル、96以上でファンブルにしています。returnのbool値はダメージ判定時に使用します。
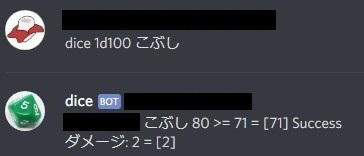
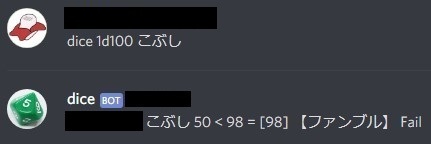
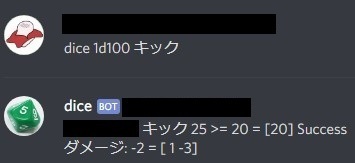
def judge(charactor, key, dice_size, dice_num): dice_val = np.array([], dtype=np.int64) for i in range(dice_num): dice_val = np.append(dice_val, dice(dice_size)) if int(charactor[key]) >= np.sum(dice_val): msg = key + ' ' + str(charactor[key]) + ' >= ' + str(np.sum(dice_val)) + ' = ' + str(dice_val) if np.sum(dice_val) <= 5: msg += ' 【クリティカル】' msg += ' Success' return msg, True else: msg = key + ' ' + str(charactor[key]) + ' < ' + str(np.sum(dice_val)) + ' = ' + str(dice_val) if np.sum(dice_val) >= 96: msg += ' 【ファンブル】' msg += ' Fail' return msg, False
discord上ではこのように見えます。

ダメージ判定
特定の技能名で技能判定が成功した際に自動でダメージロールを振るようにしました。トリガーとなる技能名はあらかじめダメージがわかっているこぶし,頭突き,キックだけに絞って実装します。マーシャルアーツは考慮していません。
ダメージボーナスがあればマイナスも含めて追加しています。
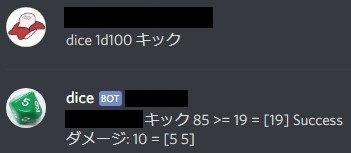
def damage(charactor, key): d = np.array([], dtype=np.int64) if key == 'こぶし': d = np.append(d, dice(3)) elif key == '頭突き': d = np.append(d, dice(4)) elif key == 'キック': d = np.append(d, dice(6)) else: return None if 'd' in charactor['db']: result = parse('{}d{}', charactor['db']) dice_size = int(result[1]) dice_num = int(result[0]) for i in range(np.abs(dice_num)): if dice_num < 0: d = np.append(d, -dice(dice_size)) else: d = np.append(d, dice(dice_size)) return d
- 成功
- 失敗
- ダメージボーナスあり
- ダメージボーナスあり(マイナス)
狂気表
discord上で次のように入力した場合に狂気票を振るようにします。
dice 1d10 狂気の種類
狂気の種類は一時的発狂と不定の狂気の2種類が振れます。1d10はフォーマットの統一の為につけていますが、実質使っていません。
一瞬、狂気表もスプレッドシートに書こうかと思いましたが、処理速度をあげる為にハードコーディングしてます(正直、面倒臭かったので)。
def temp_madness(): roll = {} roll[1] = '鸚鵡返し(誰かの動作・発言を真似することしか出来なくなる)' #(中略) roll[20] = '過信(自分を全能と信じて、どんなことでもしてしまう)' msg = roll[dice(20)] msg += '\n一時的狂気(' + str(dice(10)+4) + 'ラウンドまたは' + str(dice(6)*10+30) + '分)' return msg def ind_madness(): roll = {} roll[1] = '失語症(言葉を使う技能が使えなくなる)' #(中略) roll[10] = '殺人癖(誰彼構わず殺そうとする) ' msg = roll[dice(10)] msg += '\n不定の狂気(' + str(dice(10)*10) + '時間)' return msg
- 一時的狂気

- 不定の狂気

Herokuにデプロイする
そのままではローカルでbotを起動している時しか使えないので不便です。そこでサーバーを立てて常時使えるようにします。今回はHerokuを使います。
Procfile
まずは、Heroku上で動かす実行スクリプトを作成します。今回はtrpg_bot.pyを実行するだけなので
woker: python trpg_bot.py
とします。
requirement.txt
requirement.txtにpythonファイル内で使っているライブラリを記入します。今回は以下のライブラリを使用しています。
oauth2client httplib2 gspread discord parse numpy
デプロイ
基本的にはHerokuのアカウントを作ってCreate New AppしてHeroku Gitにしたがって進めれば良いです。
# Herokuにログインする $ heroku login # リポジトリをクローンする $ heroku git:clone -a trpg_dice_bot $ cd trpg_dice_bot
cloneしたリポジトリに作成したアプリケーションなどを格納します。
- trpg_bot.py #メインアプリケーション
- config.json #設定ファイル
- requirement.txt # さっき作ったやつ
- Procfile #さっき作ったやつ
- oauth.json #Googleスプレッドシートを作った時にダウンロードしたoauthのjsonファイルです
$ git add . $ git commit -am "make it better" $ git push heroku master
無事デプロイに成功すると
remote: Verifying deploy... done.
のようなメッセージが表示されます。 デプロイした時点ではまだdiscord上ではbotはオフラインのはずです。
有効にするには、Resourcesからアプリを起動すればdiscord上でbotがオンラインになるはずです。 ちなみにHerokuの無料枠は550時間です。

無事、オンラインになりました。
このあたりを参考にさせていただいています。
これで快適なTRPGライフが送れるはず。 少しでも誰かの参考になれば幸いです。